







PubMed, 4개월간 챗GPT 관련 141건 논문 등록
잠재력에도 학습 모델 한계 뚜렷…시간 검증 기다려야
이용자와 실시간으로 대화가 가능한 대규모 인공지능 모델 ChatGPT(챗GPT)가 미국 의사국시를 통과하면서 의료 영역에서 실제 활용성을 검증하기 위한 작업이 본격화되고 있다.
자의식이 없다는 점에서 그릇된 정보의 학습 가능성을 고려하면 엄중한 지식 및 판단이 필요한 의료 영역에서 그 활용성에 제한이 따를 수밖에 없기 때문.
다양한 범위에 걸쳐 고품질의 연구 관련 질문을 생성, 연구자에게 참신한 아이디어를 제공하는 사례가 등장한 반면 엉터리 답변을 내놓은 사례도 등장하면서 전문가들은 챗GPT의 검증에 보다 오랜 시간이 필요하다는 데 무게를 실어주고 있다.
2022년 11월 공개된 챗GPT는 대화형 인공지능 서비스로 사용자가 입력한 질문에 답하도록 설계된 언어모델이다.
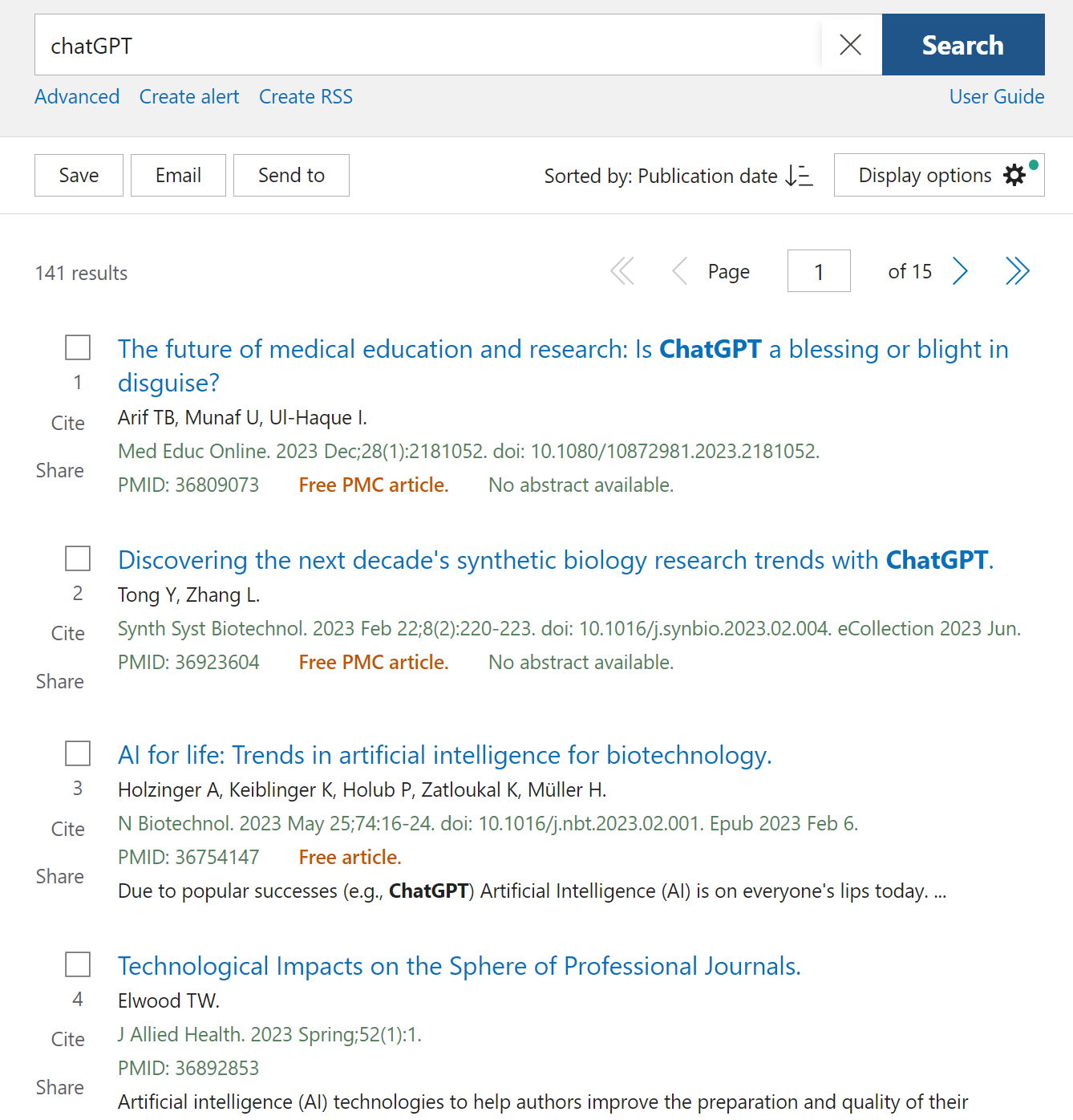
의학 논문검색 사이트 PubMed에 챗GPT 관련 연구가 첫 등장한 2022년 12월을 기점으로 총 141건의 논문이 등록됐다. 챗GPT의 등장이 4개월에 불과하다는 점에서 폭발적인 연구 증가는 의학계의 관심도를 나타내는 단면.
초기 연구가 챗GPT의 소개 및 의학적 활용성 모색에 그쳤다면 최근 연구는 실제 임상 현장, 환경을 구현해 챗GPT가 적절한 반응을 나타내는지 확인하는 '검증' 영역에 접어들고 있다.
이달 13일 공개된 연구(DOI: 10.1038/s41598-023-31412-2)는 챗GPT가 소화기내과에서 중요한 연구 질문을 도출해낼 수 있는지 평가했다.
연구진은 위장병학(GI) 분야는 끊임없이 진화하고 있어 중요한 연구 질문을 정확히 집어내는 것이 중요하다는 점에 착안, 연구 우선순위를 식별하기 위한 평가에 착수했다.
GI의 네 가지 핵심 주제인 염증성 대장 질환, 마이크로바이옴, 인공지능, 고급 내시경 등에 대해 챗GPT에 질의하고 경험이 풍부한 소화기 전문의로 구성된 패널이 생성된 연구 질문을 1~5 등급(높을수록 적절)으로 평가했다.
전문가 패널의 평가 결과 챗GPT는 관련성이 있고 명확한 연구 질문을 생성했다는 판단이 나왔다.
평균적으로 질문의 등급은 3.6±1.4 점이었으며, 관련성, 명확성, 특수성 및 독창성에 대한 평균 등급은 각각 4.9±0.1, 4.6±0.4, 3.1±0.2, 1.5±0.4점이었다. 패널들은 챗GPT가 연구 질문을 생성하는 데 명확하고 적절하지만 독창적이지는 않았다고 판단했다.
연구진은 "이번 연구는 대규모 언어 모델이 GI 분야에서 연구 우선 순위를 식별하는 데 유용한 도구가 될 수 있지만 생성된 연구 질문의 참신성을 개선하기 위해 더 많은 작업이 필요하다는 것을 시사한다"고 가능성과 한계를 동시에 진단했다.
챗GPT가 핵의학 문헌을 요약하거나 연구자의 글을 수정 및 개선하는 데 도움을 줄 수 있는지 판단한 연구(doi.org/10.1007/s00259-023-06172-w)도 지난달 공개됐다. 이번 연구에서 챗GPT는 다소 실망스런 결과를 내놓았다.
연구진은 핵의학 필기 시험을 시뮬레이션하기 위해 챗GPT에게 50개의 4~5선다형 문제를 제공하고 정답 1개를 선택하도록 했다. 50개 사례 모두에서 챗GPT는 명확한 답을 제시했지만 답안과 대조한 결과 정확도는 34%(17/50)에 불과했다.
이어 연구진은 문답 피드백 방식으로 챗GPT의 학습 능력 또는 수정 능력을 테스트했다. 틀린 대답을 내놓을 경우 다시 질문하는 방식으로 문제를 이어갔다.
"뼈 스캔에서 흡수량이 증가하지 않는 양성 병변은 무엇입니까?"라는 질문에 챗GPT는 유골종(osteoid osteoma)이라는 오답을 내놓았다. 다시 질문을 한 결과 이번엔 골관절염이라는 엉뚱한 대답을 내놓았다.
연구진은 "같은 질문을 하면 다른 답이 나타날 수 있고 몰랐거나 대답할 수 없다고 말하는 대신 챗GPT는 피상적이고 설득력 있는 답변을 제공했는데 이는 잘못된 것"이라며 "특히 이같은 행위는 스캔 결과를 해석하는 데 해로울 수 있다"고 지적했다.
연구진은 "AI 모델은 높은 신뢰도로 잘못된 출력을 생성하기 위해 (답변을) 속일 수 있으며 현재 동료 검토자를 속일 수 있는 겉으로 보기에 설득력 있는 콘텐츠를 제공할 수 있다"며 "이번 예비 분석은 현재 표준화된 시험의 환경에서 챗GPT가 핵의학 의사가 기대하는 지식을 입증하는 것과는 거리가 멀다는 것을 시사한다"고 덧붙였다.
이달 4일 공개된 연구(DOI: 10.1007/s†16-023-01925-4)는 임상 실무 지원 및 의약품 연구, 공중보건 주제에 대한 추론에 걸쳐 챗GPT의 가능성을 평가했다.
연구진은 챗GPT와 같은 AI 기반 언어 모델이 인상적인 능력을 입증했지만, 높은 수준의 복잡한 사고가 필요한 의료 분야에서 얼마나 기능을 잘 수행할지는 미지수라며 그 타당성을 조사했다.
먼저 과학 글쓰기 영역에서 챗GPT에 2022년 12월 NEJM에 발표된 논문 5편을 요약해달라고 한 결과 전반적으로 올바른 결과값을 내놓았다.
이어 공중보건에 대한 토픽에서 연구진은 챗GPT에 생물학적 관점에서 고령자의 연령을 객관적으로 측정할 지표를 물었고 이에 챗GPT는 치아 및 골격 발달, 텔로미어 길이, DNA 메틸화, 호르몬 수준, 인지 기능을 포함해 일반적으로 연구되는 방법들의 목록을 즉시 제공했다.
연구진은 "챗GPT는 문헌 탐색과 새 연구 가설 수립, 복잡한 데이터 처리에 유용할 수 있다"며 "또 전자 건강 기록(EHR), 임상 노트 및 연구 논문과 같은 의료 텍스트에서 유용한 정보를 추출하는 데도 도움이 될 수 있고 복잡한 연구를 일반 대중이 이해하기 쉬운 언어로 번역함으로써 과학적 발견의 보급을 촉진할 수 있다"고 결론내렸다.
이어 "다만 챗GPT의 한계와 능력을 이해해야 한다"며 "정확한 답변은 신뢰할 수 있는 것처럼 들리지만 부정확하거나 비논리적인 언어를 생성하는 챗GPT의 능력도 포함되고, 또 다른 큰 문제는 챗GPT가 훈련 받은 데이터에 존재하는 편견을 재현할 수 있다는 것"이라고 덧붙였다.
챗GPT를 연구 강의 자료 생성에 활용해 본 김병욱 대한상부위장관·헬리코박터학회 총무이사 역시 비슷한 의견이다.
그는 "챗GPT는 사람들이 기대하는 것처럼 기존의 연구를 토대로 새로운 내용의 임상 논문을 쓰거나 새로운 개념, 아젠다를 제시할 정도의 성능은 아니었다"며 "강의 자료 요약하는 부분에서 활용할 부분이 있다는 생각이 들었을 뿐 챗GPT가 창의적으로 기존 문제들을 해결해 줄 돌파구라는 기대감은 과하다"고 덧붙였다.