







1만개 피부경 검사 이미지 활용한 비교 연구 결과
챗 지피티 그나마 공정성 확보…라바 등 연령 편향
생성형 인공지능(AI)으로 불리는 멀티 모달 거대언어모델(LLM)이 의료 분야로 영역을 확장하고 있지만 여전히 편향 문제를 가지고 있어 주의가 필요하다는 지적이 나왔다.
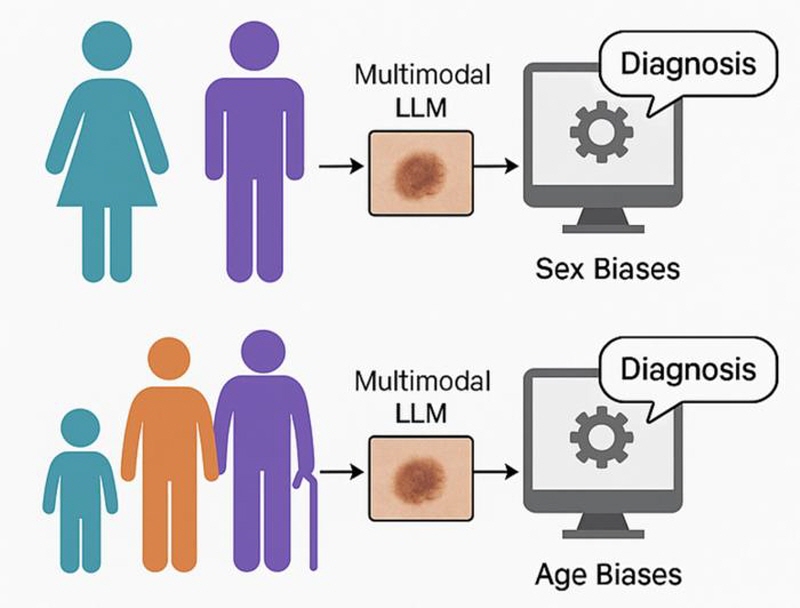
질환 진단에 있어 성별이나 연령 등의 변수를 반영하지 못해 잠재적 편향이 나타나는 만큼 임상 적용에 앞서 이를 해결해야 한다는 것이 전문가들의 의견이다.
현지시각으로 28일 국제학술지 헬스 데이터 사이언스(Health Data Science)에는 거대언어모델의 편향성에 대한 대규모 연구 결과가 공개됐다(10.34133/hds.0256).
현재 챗 지피티(Chat GPT)를 비롯한 거대언어모델은 의료 분아에서 복잡한 질문에 전문의 수준으로 응답하며 잠재력을 인정받가 활용도가 높아지고 있다.
이로 인해 이미 이를 의료 분야에 적용하기 위한 노력이 이뤄지고 있으며 신뢰성을 확인하기 위한 연구도 이어지고 있는 것이 사실.
하지만 일부 연구에서는 여전히 거대언어모델의 한계로 꼽히는 환각과 편향이 나타나면서 이에 대한 우려의 목소리도 나오고 있는 것이 현실이다.
상하이기술대학교 완 지위(Zhiyu Wan) 교수가 이끄는 연구진이 이에 대한 대규모 연구를 진행한 배경도 여기에 있다.
실제로 챗 지피티를 비롯한 거대언어모델이 의학 분야 적용에 있어 편향성을 가지는지를 파악하기 위해서다.
이에 따라 연구진은 흑색종과 양성 각화증, 멜라닌세포 모반 등을 포함하는 1만개의 피부경 검사 이미지를 대상으로 널리 쓰이고 있는 거대언어모델인 챗 지피티(ChatGPT-4)와 라바(LLaVA-1.6)의 성능을 테스트했다.
그 결과 거대언어모델은 이미 딥러닝 모델의 성능은 크게 앞서고 있었다.
합성곱 신경망(CNN)을 기반으로 하는 3개의 딥러닝 모델(VGG16, ResNet50, Model Derm)을 포함해 하나의 트랜스포머 모델(Swin-B)을 비교한 결과 정확도에서 앞섰기 때문이다.
실제로 챗 지피티는 가장 성능이 좋은 CNN에 비해 3% 더 높은 전체 정확도를 보였고 라바는 마찬가지 비교에서 23%나 정확도가 높았다.
하지만 거대언어모델의 한계로 꼽히는 편향성 부분에서는 아쉬움을 남겼다.
챗 지피티의 경우 흑색종 식별에서 높은 정확도를 보였으며 특히 젊은 층에서 인공지능의 정확도를 의미하는 AUROC가 0.792로 상당히 높을 수치를 기록했지만 중년층 연령의 경우 정확도가 0.187로 크게 내려갔다.
반면 라바의 경우 노인층에서는 AUROC가 0.813으로 매우 높은 정확도를 보였지만 젊은 연령에서는 0.208을 기록하며 마찬가지로 큰 차이가 나타났다.
다른 요인을 모두 제외하고 순수하게 공정성 면을 평가하면 그나마 챗 지피티는 다른 딥러닝 모델보다도 가장 높은 공정성을 보였지만(P< 0.05) 라바는 P값이 0.005로 성별, 연령별 그룹간에 유의미한 편향을 보였다.
연구진은 이를 기반으로 거대언어모델을 의료 분야에 제대로 적용하기 위해서는 이같은 편향 문제를 선결해야 한다고 강조했다.
완 지위 교수는 "챗 지피티와 라바 모두 딥러닝 및 트랜스포머 모델보다 더 높은 정확도를 보인 것은 매우 고무적인 일"이라며 "상당한 잠재력을 가지고 있다는 것을 의미한다"고 설명했다.
그는 이어 "하지만 여전히 성별, 연령별 특징에 따라 편향성이 분명히 나타난 것은 아쉬운 부분"이라며 "의료 분야에 이를 적용하기 위해서는 이러한 편향을 해결하는 것이 선행 과제"라고 밝혔다.